

Fred Slota
-
Posts
1,131 -
Joined
-
Last visited
-
Days Won
16
Content Type
Profiles
Forums
Blogs
Downloads
Posts posted by Fred Slota
-
-
Repeating my opinion that declaring an issue to be the second printing of a particular variant implies the existence of a first print of the same variant. The above, and others, in my opinion should be reassigned as second printings of the /A variant.
-
Is officially entered in CB as my suggestion.
Thank you.
-
X-Force 1/F still exists, but the note that must have identified the Deadpool Card appears to have been cleared.
Voiced consensus is that this is not a real item, and is a duplicate of #1-2 and should be removed.
-
Issue was moved at some point. Thank you.
Submitted with a note reading:
Cover has issue number of "65.Deaths" -
Now reported for duty. Thanks.
-
Gone. Thanks.
-
I've been continuing to have this issue since I first posted.
I've finally decided to switch my backups to the SSD (which is not One Drive mirroring) to see what happens.
Just closed, backup is saved, 7-zip has been running for several minutes, taking a good chunk of CPU%, but without visible impact; mouse still reacts, YouTube still plays, I'm currently typing this post with no perceptible issues.
-
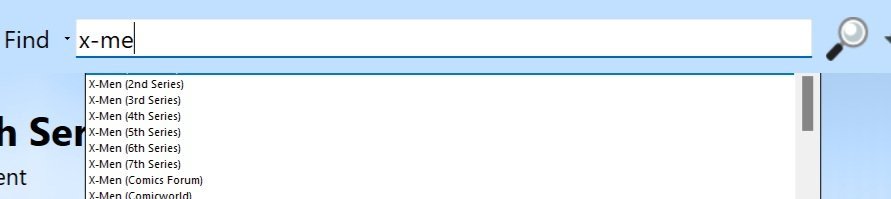
Your drop-down is complete and starts immediately under the Find Bar, yes?
-
Updated to 25.6.3.4438
Flickering never-filling progress bar for downloading comic book cover images still there.
-
I have noticed the new feature, and this is probably a side effect of the new feature. But, because you think I am describing the new feature, you are not paying attention to problem I am describing.
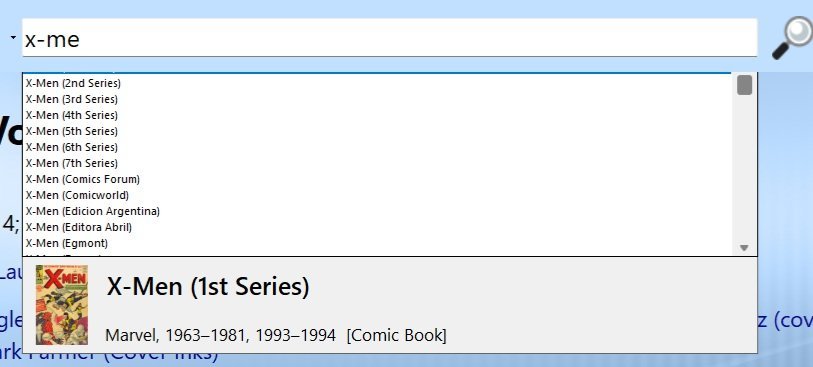
The top of the drop-down list is missing. The first entry on the list is not visible. Let me include a larger snippet, with my mouse hovering over the scroll bar.

I have typed "x-me" and the list has populated.
The details for "X-Men (1st Series)" are shown under the drop-down list, so that title must be the highlighted first entry in the list.
But, you can't see it on the top of the list.
Notice that the scroll bar on the right is showing the down button on the bottom, but not the up button on the top.
The first entry in the list is not showing.
If I down arrow, it highlights the visible "X-Men (2nd Series)" and the details under the list reflect that highlight.
If I then up arrow, I can no longer see what is selected, but the details under the list revert to "X-Men (1st Series)"
-
v25.6.3.4378
Type "X-Me" in the Find bar, the top return should be "X-Men (1st Series)", but I wouldn't know it, since the top entry is not showing.
It is there, since if I down arrow, it selects "X-Men (2nd Series)", and if I then up arrow, it selects "X-Men (1st Series)"

-
Looking closer, it appears that there is a variant, Digital.
Assuming this is meant to be used for digital copies, I think this title should record the physical hardcover book as "Bk 1/HC", and the digital copies as 1/Dig, 2/Dig and 3/Dig. This will clarify that "Bk 1/HC" and 1/Dig are not variants of the same item, that is, do not have basically equivalent contents. The Notes for the three digital copies should indicate that they are 3 parts of the original Hardcover, and should separately list their contents.
-
 1
1
-
-
So, physical-book-wise, this is a series of 1, which happens to be Hard Cover, so 1/HC should exist, and 2/HC and 3/HC do not.
e-books, an area of ComicBase I have no familiarity with. How does ComicBase support them at the moment, if at all?
-
Also, JSA (2nd Series) #8/A-8/B
-
I'm a little confused... here's the first line of the Title description:
(From the publisher)
Every AVX tie-in, collected in one massive volume!
Yet the title has 3 issues, 1/HC, 2/HC and 3/HC.
1/HC has the following in Notes:
Collects Avengers Academy #29-33, Secret Avengers #26-28, Avengers (Vol. 4) #25-30, New Avengers (2nd Series) #24-30, X-Men Legacy #266-270, Wolverine & the X-Men #9-16, 18, AvX: Consequences #1-5, Uncanny X-Men (2nd Series) #11-20 and A-Babies vs. X-Babies #1
Which matches the complete list at the end of the Title descrption.
So...
-
Probably others, but found these...
Angel (Boom!) #1-2
Charismagic #0-2
The Dark Crystal: Age of Resistance #1-2
Doctor Who: The Eleventh Doctor #1-2
Fairlady #1-2
Farscape #1-2
Flash Gordon (Dynamite) #1-2
Gatchaman #1-2
Horizon Zero Dawn#1-2
Kirby Genesis: Silver Star #1-2
Lady Mechanika #1-2
Mighty Morphin Power Rangers (5th Series) #0-2
New Gods (5th Series) #2-2
Project Superpowers: Blackcross #1-2
Red Sonja (Dynamite, Vol. 3) #1-2
The Spider (Dynamite) #1-2
The Spirit (11th Series) #1-2
Transformers: Unicron #1-2
True Blood #1-2
Wonder Woman (6th Series) #1-2
-
Appears to be MIA, at least at the moment...
-
The series looks to run through #32 with multiple variations, and then has a random issue random variation just hangin' out...
Looks like a copy hopped over from "Archie" to "Archie (Vol. 2)"
-
Why does the report give the NM price for all items, when the items it is reporting include a condition, which might not be NM? Why does the report not show the Price adjusted for the condition?
Can I generate an Item Checklist report in Selling Price, not NM Price?
-
Mass Change. Got It.
Forgot it existed, since it's such a nuclear option I don't play around with it.
My Wanteds are of a more manageable number, so I've been doing Searches and Quick Change to clear and copy to CustomCheck3. I'll play with it later. Thanks.
-
I already copy my "Wanted" field into CustomCheck3 before generating the report for export.
I assume if I want access to the Cover Date, I will need to copy this to, say, CustomDate2.
Is there an easy way to Copy all Cover Dates to CustomDate2? I only need/want they cover dates for all issues, owned or not, in series that I own at least one issue, so if there is an easy way to copy only in those Titles, that can work, too.
-
Bad adjustment happened again...
Renamed Comic Book Titles
All-New Wolverine Saga -> 1939 Daily Bugle
-
I too was just seeing this. Closed the program, reopened, and it was still happening.
Program update with v25.6.3.4315, and Find Bar searching was working again.
-
And, applied an update to v25.6.3.4085 before applying a new content update.
Still stuttering, barely-filling 'progress' bar when "downloading new comic book cover images xxx/1812. Also noticed the window title read "0% of Progress" throughout the whole process.
I have a guess of what's happening. I think the bar is zeroing at the start of each new image download and trying to animate to the current progress percentage, but if the next image downloads quickly, then it re-zeroes having barely animated. I think I noticed a few times when an image took a little longer to finish and the next one start, and the progress bar seemed to animate further along before being re-zeroed.
Avengers vs. X-Men Companion
in Content and Corrections
Posted
Poke.