Leaderboard




Popular Content
Showing content with the highest reputation since 7/13/2024 in all areas
-
New title added to Books: The Frazetta Pillow Book This title has one item listed, TPB #1. Is this book actually part of a numbered series? (I ask b/c there is no number on the front cover scan and there are no other items under the title.) New title added to Books: The Lost Frankenstein Pages Two items listed under this title: TPB and #0/A. That seems an odd way to list these items when the only difference between them is the signed, loose bookplate. (See this thread for more info) I would have assumed they would be listed as TPB and TPB/A. New title added to Comics: Marvel All-On-One (3rd series) This is the first series with this title. (Perhaps somebody in the CB editorial bullpen was thinking of "Marvel Two-in-One" while setting up this title?) New title added to Comics: Metal Hurlant (Humanoids 2nd Series) This looks like a duplicate of the comic title Metal Hurlant (2nd Series) that was added to the database very recently. One of the two titles needs to be deleted.2 points
-
New comic title: Archie Meets Jay and Silient Bob That should probably be Archie Meets Jay and Silent Bob (fixing the typo in "Silent")2 points
-
@Gregory Hecht done @Chris Prasol your submissions will be processed by our editorial team and be included in our next weekly content update. Thanks for your contributions2 points
-
The following new titles were added in the Comic Books category, but they probably belong in the Books category instead: Farscape: Script Book Naughty Faeries Stripper Book NFSA WSPT Artbook Scream Queens Sketchbook Still Ill Calendar2 points
-
I think this is a book containing nothing but blank pages. It is to be used for you to draw your own images or get artists to draw on the pages. And Dinosaur Comics Sketchbook isn't the only one that Antarctic press put out. There is a Horror Comics and a Jungle Comics. Here is a link to eBay. https://www.ebay.com/itm/226518857624?_skw=ANTARCTIC+PRESS+-+BLANK+SKETCH+COMIC+BOOK+-+DIY+-+CREATE+YOUR+OWN+-+NM+-+2016&itmmeta=01JJMGEX43ZGZ4AS0YHTK3Y4XR&hash=item34bd937798:g:WmsAAOSwe0hncXS0&itmprp=enc%3AAQAJAAABMHoV3kP08IDx%2BKZ9MfhVJKnL01GV1nLC4NkII%2BLjRW4pmhwdCttmX6niSIjZOi%2FCbGuK3Y09REQLuAWGpntgrP%2FV63QkD9dficBLjb3CORkJQAMY%2FidE9UM4XPkqjIk3L%2FWXFoGpcNg1CV%2Fd%2FkWzj%2BQz2tohS2Fl9IPTbUB5S%2BrisLg%2FsHSSZ1cvVgfC8VQvLU5%2BFSIZ8q40lG6j%2FxFOEEPcW8gWU1qtNbsFi1HCpkFvEOknRiWvUn%2Fp%2Fj7duSAZbQMvk3SM52ZHMVMnA304gweByzqkL%2FsjgJBKu1ecODWz9Rl5408GZGQKbWgCoWPIxo%2FDO45WLRmXS24wYYvCNUoNfop%2Br8XDiAZkQkeSnZGNIVbOwhDGQsCwQyXMptZQI3VgfD2Xc6upkzh9JDPEr5I%3D|tkp%3ABk9SR5bSu5CVZQ (a couple let you see the blank pages inside)2 points
-
From a netiquette perspective, it is preferred that you post within a thread you have started for this topic rather than start a brand new thread for the exact same topic. This is the second time that I have merged one of your posts into the original thread. As to your original question, my personal opinion as a CB user (I'm not a Human Computing employee and do not serve any formal role on the CB editorial team) is that while it is obvious which comics would qualify as a "major key" (e.g., Action Comics #1, Amazing Fantasy #1, Showcase #4, etc.) there will always be some subjectivity as to which comics constitute a major key and especially what should count as a minor key. Is Thor #337 a major key or a minor key? If you choose minor key, does that change if Beta Ray Bill gets a starring role in an MCU movie or TV show? What about Amazing Spider-Man #545? It's not expensive on the back market, but it is a key moment in Spider-Man history and continuity (even if it is not necessarily a popular moment). Wolverine's first appearance was only a cameo in Incredible Hulk #180. Presumably #181 is a major key, but is #180 a major key b/c it is the true first appearance or is it a minor key b/c it is only a couple of panels? Wolverine has a similar cameo in Incredible Hulk #182... is that a minor key or not a key? Should keys for non-super-hero comics be included? So does Bone #1 (1st printing) count as a major or minor key? What about subsequent printings of Bone #1? Do all of the first issues of EC's "New Trend" titles get labeled as major keys? What about the first issues of EC's "New Direction" titles? Is Sugar & Spike #1 a major or minor key? Do non-English comics get "key treatment" for the first appearances of One Piece, TinTin, or Asterix? What about various issues of Weekly Shonen Jump from Japan (such as #43 that introduced Naruto) or the reprints of those stories that Viz published in Shonen Jump in North America? Captain Underpants and Dog Man are really popular, so the first appearances of those characters should probably be labeled as a "key" in some way... but there are people who argue that those characters aren't enough like comic books to warrant that kind of attention (even if the CB database categorizes them under Comics rather than Books). To varying degrees, a lot of major and minor keys are in the eyes of the beholder. I wouldn't want to speak for Pete, but my guess (and I emphasize that this is a **guess**) is that with everything that the CB editorial/corrections team needs to field each week, adding editorial decisions about what is (or is not) a major or minor key is something that would eat up a ton of the team's time without a lot of "value added" to the CB product. YMMV, of course.2 points
-
Details here: https://bleedingcool.com/comics/dc-comics-at-dollar-tree-for-a-dollar-twenty-five-cents/2 points
-
EC Comics is back (sort of) with two entirely new titles being published by Oni Press. It looks like there was some confusion as to the titles. There is "Epitaphs from the Abyss" and "E.C. Comics: Epitaphs from the Abyss." The indicia reads "Epitaphs from the Abyss" and the publisher is Oni-Lion Forge Publishing Group. The "E.C. Comics Epitaphs..." entry in CB has just Oni as the publisher. I get the impression that the current and correct entry is the title without the "E.C. Comics" at the beginning because it has no pictures in its file and the other title has a couple. The other new title is "Cruel Universe" which is in CB as "E.C. Comics: Cruel Universe" with Oni as the publisher. The indicia reads "Cruel Universe" with Oni-Lion Forge Publishing Group as the publisher. My recommendation is to make the entry for "Cruel Universe" the same as "Epitaphs from the Abyss," dropping the "E.C. Comics" from the title and adding Oni-Lion Forge as the publisher.2 points
-
The 2/20 update also adds a new edition of Clyde Fans by Seth under that title. Previous editions of Clyde Fans are listed, correctly or incorrectly, under Palookaville as Bk 2/HC, CS 1, and CS 2, because the material was originally serialized in issues of that title. For consistency, either those earlier versions of Clyde Fans should be moved to the new title, or the new edition should go under Palookaville with the others. For now, I've submitted item titles for the books listed under Palookaville, because they aren't really labeled as Palookaville and it's not obvious that they would be listed there.1 point
-
Minky Woodcock: The Girl Who Electrified Tesla Book #1 and Book #1/HC appear to be the same item: they have the same cover price and cover scan. I am also unable to find evidence of a paperback version of this collection, suggesting that Book #1 should be deleted from the database and Book #1/HC should be retained.1 point
-
Just about all the sites I search for (that don't have it all in upper-case) has it as Toxic Daughter: Chi-chan (lower-case 'c'). Since it a pre-order, there are not insides looks that I can find to verify one way or the other.1 point
-
Also added in the latest update was the Comic Book title Conan the Barbarian Colossal Edition. There are four cover variants of this one: • a Barry Windsor-Smith cover (which is listed in the database as #1/HC; listed as "A" in the indicia); • a John Buscema cover (not in the database; listed as "B" in the indicia); • a Jim Lee cover (not in the database; listed as "C" in the indicia); • and a Neal Adams cover (not in the database; listed as "D" in the indicia). I submitted the Buscema cover edition from my database as #1/A, but upon further reflection I think that the #1/HC should be deleted and the four cover versions should be listed as #1/A through #1/D just as they are in the indicia.
 1 point
1 point -
Try these steps: First, make sure you've installed CB2025 on the new computer. Next, follow these steps to transfer your database from your old computer to the new using a USB thumb drive: Launch ComicBase on your older computer and make sure your main database is loaded in Next, Go to the File > Save a Copy to save your database to the USB thumb drive. Give your database a new unique name so its easy to locate (ex: Dan's Comic Collection). Onced saved, safely remove the USB thumb drive from the older computer. insert the USB thumb drive in the new computer, Locate the database file on the thumb drive and copy it over to the following folder location: Documents \Human Computing\ComicBase Databases folder Once the database has been copied, double-click on it and it should automatically load into ComicBase 2025 on the new computer If you're still stuck and not able to proceed, feel free to give our tech support team a call at 408-266-6883 (M-F, 9am to 5pm PST)1 point
-
Dark Horse has cancelled Anansi Boys #8 and the hardcover collection of the series. They are not planning to resolicit. Issues #8/A and #8/B should be deleted from the database. The hardcover was solicited, so if that ends up in the editorial queue for a content update it should not be added into the database.1 point
-
moving to Books next content update1 point
-
Newly added Book title National Lampoon Comics: the contents of this appear to be comics based on an Amazon preview (and the CB title description calls it an "anthology of comics"), so I suggest that this should be moved to the Comics media category. Newly added Comic title Silly Symphonies: A Companion to the Classic Cartoon Series (Walt Disney’s…): based on the cover scan, this looks to be a duplicate of the already existing comic title Walt Disney’s Silly Symphonies 1932-1935: Starring Bucky Bug and Donald Duck. Newly added Comic title Unforegettable Con, The: note that this contains a spelling error (should be Unforgettable Con, The ). Newly added Comic title New York Comic Con: What is this? Is this a convention program, a comic, or a promotional pamphlet of some sort?1 point
-
Some more clean-up for the 1/17/2025 content update: The newly-added title Beetle Bailey: Strategic Withdrawl has a spelling error and should instead be listed as Beetle Bailey: Strategic Withdrawal. The new title Big Nate Attack of the Cheez Funk Breath! needs a colon after "Nate" to make it Big Nate: Attack of the Cheez Funk Breath!. The new title Foothold: Rigsby W.I. should not have periods in the postal abbreviation for Wisconsin. Also, this is apparently going to be the first of a series of Rigsby WI graphic novels, with Foothold only being the title of Volume 1 (see the cover image). So the series title should be Rigsby WI. Going by the cover image, the new title Magnificent McCoys should be Magnificent McCoys, The. The new title Monster High Bull's Eye needs a colon after "High" to make it Monster High: Bull's Eye. The newly-added title Spitball A CCAD Comics Anthology needs a colon after "Spitball" to make it Spitball: A CCAD Comics Anthology. The title Thun’Da, King of the Congo (Magazine Enterprises) was added, but this series already exists in the database under its parent title A-1 Comics, so this newly-added title is a duplication. See A-1 Comics #47, 56, 73, 78, 83, and 86. This is confusing, but I believe cases like this are why the Item Title field was added. The new title What Would Blueys Mum Do is missing the apostrophe in Bluey's, and it is a picture storybook rather than a comic book, so it belongs in the Books category.1 point
-
I added the Title and basic information for this. Should (hopefully) show up in the next update.1 point
-
I added that one. New York Comic Con is the unfortunately generic title in the indicia for an ashcan-sized comic from Virgin Comics that includes the first several pages of their then-new series Dock Walloper and Dan Dare. This info is in the Notes field of the entry I submitted.1 point
-
I usually wait to hop on to one of @Gregory Hecht's posts, but he hasn't done one for the 1/09/2025 content update yet, so I guess I'll start: The book title The Marvel Art of David Finch was added. This should follow the usual format of Marvel Art of David Finch, The. The comic book title All in Saga was added. When "in" is used as a preposition in a title, it should not be capitalized. But here, I believe "in" is being used as an adverb, and as such it should be capitalized in a title. So it should be All In Saga. The title Avengers: Assemble TPB was added to the Comic Books category. Should this book be instead listed under one of the existing Avengers: Assemble series? The title DC X Sonic the Hedgehog was added. I confess that I find the relatively recent convention of using "X" instead of "&" or "/" a bit annoying, but I wonder if it's meant to be "X" (uppercase) or "x" (lowercase) or "×" (multiplication symbol). I don't know if there's even a way to tell. In the new title Deadpool Kills The Marvel Universe III, the word "the" should not be capitalized. The title Drumming Up an Appetite With Vinnie Paul was added to the Comic Books category, but it appears to be a cookbook, not a comic book. In the new title Free For All, the word "for" should not be capitalized. In the new title Heroes Of Echo Company, the word "of" should not be capitalized. The new title Presents (Jim Henson’s…) should be Presents (Jim Henson…)--no possessive. The title Romero’s Axa Classics was added. I only see this elsewhere as Axa Classics. But if Romero's is part of the title, then the ComicBase convention would be Axa Classics (Romero's…) . The new title Smurfs, The: Who’s Is That Smurf? should be Smurfs, The: Who Is That Smurf? . The magazine title Hero Special Edition Vol 3 was added. From what I can tell, this should instead be listed as Hero Illustrated (Volume 3). I'm basing this on the model of Hero Illustrated (Volume 2) and its existing entry.1 point
-
Actually, since it is not a possessive, it should not be in parenthesis and just be 'Jim Henson Presents'. (I have mentioned this to Mark).1 point
-
This week's update added the Comic Book title Amazing Spider-Man, The: 65 Deaths. My understanding is that this actually another one of those ##.whatever type issues of Amazing Spider-Man. In other words, this is supposed to be Amazing Spider-Man #65.DEATHS, just like there was (for example) an Amazing Spider-Man #16.HU (indexed as Amazing Spider-Man #16.1) and Amazing Spider-Man #78.BEY (indexed as Amazing Spider-Man #78.1)... so I think that this particular issue should be indexed as Amazing Spider-Man, The (6th series) #65.1 I see that the 21 Down Complete Collection book got moved to the existing 21 Down title. The Notes field for this item still refers to "the unpublished issue #13." Issue #13 has been published, it just wasn't published in 2003 and wasn't published by DC. It exists and is in the database. The Notes field should be corrected to read "Collects 21 Down #1-13" or, if need be, "Collects 21 Down #1-12 plus #13." This week's update also added Marvel Masterworks: The Fantastic Four #25/HC. The earlier entry of regular issue #25 needs to be deleted.1 point
-
CB does not make any distinction between Direct market and Newsstand issues.1 point
-
Reported this to the programming team but no timetable to address the issue for you. Its tricky according to them as a 1 monitor setup is still the norm for most of our users (2 monitor setup maybe which CB handles pretty well). *Would recommend emailing the support team directly at support@comicbase.com and note the monitors involved, your video card(s) type, resolution settings for all monitors, and anything else relevant to help them address the issue for you.1 point
-
"Mr. Garcin" is the pseudonym of Pascal Garcin. Opinions may differ on whether the database should have him as Pascal Garcin (my preference) or "Mr. Garcin," but "M.R. Garcin" would definitely be wrong.1 point
-
I would argue that the programming behind CB should be updated to sort that out properly.1 point
-
You're talking about the 2005 series published by Dark Horse?1 point
-
BTW... love the program. I have not looked at my collection since around 1980. The process of inventorying my collection is bringing back a lot of memories.1 point
-
To get into the details of what's new: - Express+ (the new name for Express) now includes Over 200,000 cover thumbnails from Marvel, DC, Dark Horse, Image, IDW, Boom, and Dynamite -- as well as the #1 issues of all titles in the database - It also now includes (and gets updates for) cover artists for all issues. Previously, this was one of the creator fields which only was included in Pro and up editions. -Pete1 point
-
Express and Express+ are basically the same. The + indicates an upgrade to include more cover scans. ("Over 200,000 cover thumbnails to help you identify comics and variants").1 point
-
Correct. It was posted on the CB website that there would be no Livestream or Content update this week.1 point
-
I checked that out. I took a NM issues in one of the higher ranges, changed grade to F and it changed its location to a different (lower) value range. If it was based on NM value, then it should not have changed range location. It won't hurt to run menu item File->Rebuild Lists checking the Item Information box (which recalculates totals among other things).1 point
-
Editorial team will look into adding this with this week's content update. Should be easy to find by searching by its full barcode number.1 point
-
I have the same problem. It was working before the last update.1 point
-
Mark, if you have one (or more) of these British issues, can you determine/supply the Publisher? If you can, I will see about adding the title and Issues I can find.1 point
-
The title Comic Art (Comic Art Magazine) is currently housed in the Comic Book category. It should be moved to Magazines.1 point
-
Try Doctor Who (5th Series) issue SE 2013/A.1 point
-
Can you post the solution? PS This Advanced Find can display issues that are duplicates based in Title, and Item # : Items Where: I.Title || I.IssueNum || I.ItemType || I.Variation || I.Printing IN ( SELECT A.Title || A.IssueNum || A.ItemType || A.Variation || A.Printing FROM ComicIssues A WHERE I.Title = A.Title AND I.IssueNum = A.IssueNum AND I.ItemType = A.ItemType AND I.Variation = A.Variation AND I.Printing = A.Printing GROUP BY A.Title, A.IssueNum, A.ItemType, A.Variation, A.Printing (add ,I.Condition) HAVING COUNT(*) > 1 ) Order By: ComicTitles.AlphabetizedTitle, I.ItemType, I.IssueNum, I.Variation, I.Printing If you have Multiple issues with different Conditions: I.Title || I.IssueNum || I.ItemType || I.Variation || I.Printing || I.Condition IN ( SELECT A.Title || A.IssueNum || A.ItemType || A.Variation || A.Printing || A.Condition FROM ComicIssues A WHERE I.Title = A.Title AND I.IssueNum = A.IssueNum AND I.ItemType = A.ItemType AND I.Variation = A.Variation AND I.Printing = A.Printing AND I.Condition = A.Condition GROUP BY A.Title, A.IssueNum, A.ItemType, A.Variation, A.Printing, A.Condition HAVING COUNT(*) > 1 ) Order By: ComicTitles.AlphabetizedTitle, I.ItemType, I.IssueNum, I.Variation, I.Printing1 point
-
This week's update also added Batman: The Animated Series Official Coloring Book to the Comic Books category. This item likely belongs under Books instead.1 point
-
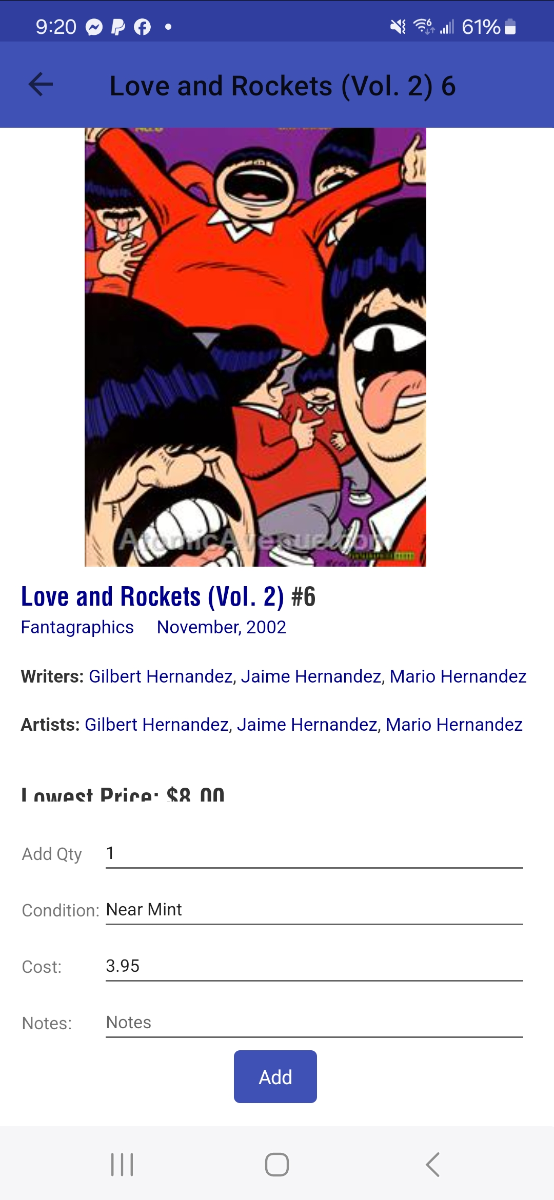
When I'm out somewhere and thinking about buying a comic, I often use the app to check on whether I already have it and, if so, in what condition. If I don't have it, I like to check what the guide says the value is, and additionally, if copies are for sale on Atomic Avenue, I like to click through and see what's being offered. It seems that, with the latest update, I am unable to take that last step. When I use the app to look up a title and then click on an issue to see details about that particular issue, there is a link that might say "2 copies on Atomic Avenue." Then when I click the link to Atomic Avenue, the bottom third of my phone screen is occupied by an Add section with four fields and an Add button. This section covers up the Atomic Avenue inventory details and I can't find a way to dismiss it. For an example, see the image below. I do not yet sell on Atomic Avenue and do not want the Add section to be displayed automatically. I would really like to see the Atomic Avenue cost and condition details instead. At the very least, I would like the Add section to have a Cancel or Dismiss button to make it go away and let me view the obscured information.
1 point
-
UPDATE: I have submitted information for the new 2024 editions of Marvel Masterworks: The Avengers vol. 2 and Marvel Masterworks: The Incredible Hulk vol. 1. They were entered as follows: • Marvel Masterworks: The Avengers #2/D for the silver & black dustjacket edition (somebody else will need to submit a cover scan and a UPC number) • Marvel Masterworks: The Avengers #2/E for the marble dustjacket edition • Marvel Masterworks: The Incredible Hulk #1/D for the silver & black dustjacket edition (somebody else will need to submit a cover scan and a UPC number) • Marvel Masterworks: The Incredible Hulk #1/E for the marble dustjacket edition1 point
-
Issues of Star Trek #500 are listed under both Star Trek (5th series) and Star Trek (6th series). I suspect that the proper place for #500 is under the "6th series" title since that is the currently published title (which I suspect is a similar rationale as to why the Star Trek #400 stunt issue was placed under the "5th series" title back when that came out).1 point
-
The best thing to do is: Open ComicBase Use menu item File->File tools. Click on ComicBase Database Manager. Click Yes to allow CB to close and have the Database Manager search your hard drives for anything that looks like a CB database. Look through the list generated and select your database.1 point
-
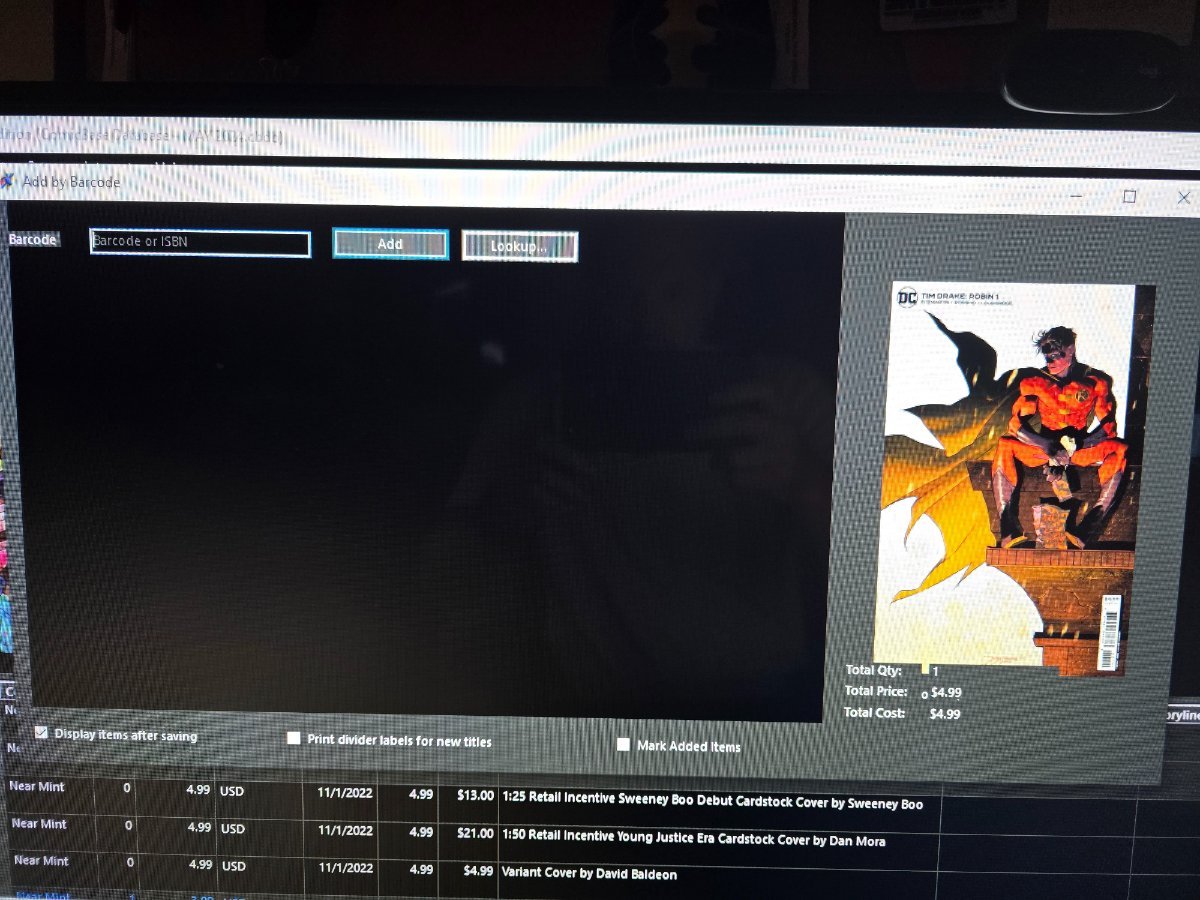
Hello, When I try to add by barcode, the list looks off and the SAVE button is missing. I contacted tech support and they recommended going to FILE TOOLS and resetting my preferences. That did not help. Windows 10, Comicbase 2025 Archive Edition with latest updates. Display drivers are updated as well Any ideas?
1 point
-
good catch... will notify the programming team1 point
-
Pete thinks he's figured it out. Should be good to go.1 point
-
thanks for spotting this one... we'll get it removed1 point
-
I would like to suggest in between raw grade selections. I know its customizable and I can add them to myself, but I'd wouldn't mind seeing these as a standard. GD/VG VG/FN FN/VF Or perhaps a little more granular. GD- GD+ VG- VG+ FN- FN+ VF- VF+ Thanks for the consideration.1 point
-
So here what I don't understand about this report. Report>Top Gainer and Losers, You want it to show "owned Items" so you can see what your top Gainer's and Losers are in your collection, great! So I have Avengers 1 CBCS 1.0 it list this book as a Previous Amount of $37,700.00 and Current Amount of $39,100.00 %increase 4%. But should it not show what the value of the book is you own? Rather than the general NM value of Comicbase.1 point
-
Find All My Owned With Cover Date For A Year (2017) & Sorted By Value Items Where... I.[CoverDate] >= "2017-01-01" and I.[CoverDate] <= "2017-12-31" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Platinum Age Comics & Sorted By Value Items Where... I.[CoverDate] > "1897-01-01" and I.[CoverDate] < "1938-03-31" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Golden Age Comics & Sorted By Value Items Where... I.[CoverDate] > "1938-04-01" and I.[CoverDate] < "1956-08-31" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Silver Age Comics & Sorted By Value Items Where... I.[CoverDate] > "1956-09-01" and I.[CoverDate] < "1969-12-31" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Bronze Age Comics & Sorted By Value Items Where... I.[CoverDate] > "1970-01-01" and I.[CoverDate] < "1984-12-31" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Modern Age Comics & Sorted By Value Items Where... I.[CoverDate] > "1985-01-01" and I.[CoverDate] < "2050-01-01" and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Comics Of Low Value/Reading Value & Sorted By Value Items Where... I.[Price] < 2.00 and I.[QtyInStock] > 0 Order By I.[Price] desc Find Every Singled Annual Published By Marvel Comics & Sorted By Value Items Where... ComicTitles.Publisher = 'Marvel' AND [ItemNumber] LIKE 'Anl %' Order By I.[Price] desc Find Every Singled None-Variant Comic Published in 2020 Who's Value At Least $50 Greater Than Original Cover Price & Sorted By 2020 Value Items Where... I.[CoverDate] >= "2020-01-01" and I.[CoverDate] <= "2020-12-31" and I.PRICE -I.[CoverPrice] > 50.00 and I.[QtyInStock]>=0 and I.[ItemNumber] not like '%/%' Order By I.[ValueYear4] desc Owned Comics That Have SUPERMAN...Starting Title & Sorted By Value Items Where... I.[Title] LIKE 'SUPERMAN%' and I.[QtyInStock] > 0 Order By I.[Price] desc Owned Comics SINCE 2000 That Have Had At Least A $20 Value Increase Over Previous Year & Sorted By Value Items Where... I.[CoverDate] >= "2000-01-01" and I.PRICE - I.[ValueYear3] > 20.00 and I.[QtyInStock] > 0 Order By I.[Price] desc1 point